Histogram MatchingWritten by Paul BourkeJanuary 2011
Histogram matching is a process where a time series, image, or higher dimension scalar data is modified such that its histogram matches that of another (reference) dataset. A common application of this is to match the images from two sensors with slightly different responses, or from a sensor whose response changes over time.
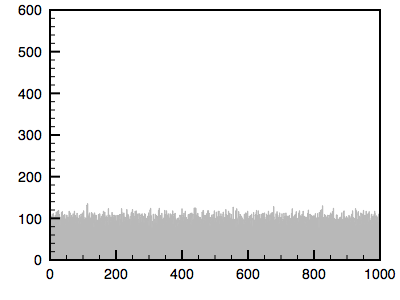
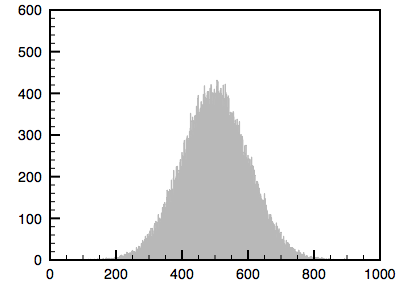
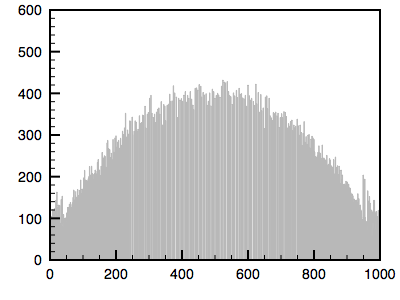
The algorithm is as follows. The cumulative histogram is computed for each dataset, see the diagram below. For any particular value (xi) in the data to be adjusted has a cumulative histogram value given by G(xi). This in turn is the cumulative distribution value in the reference dataset, namely H(xj). The input data value xi is replaced by xj. In practice for discrete valued data one does not step through data values but rather creates a mapping to the output state for each possible input state. In the case of an image this would be a mapping for each of the 256 different states. 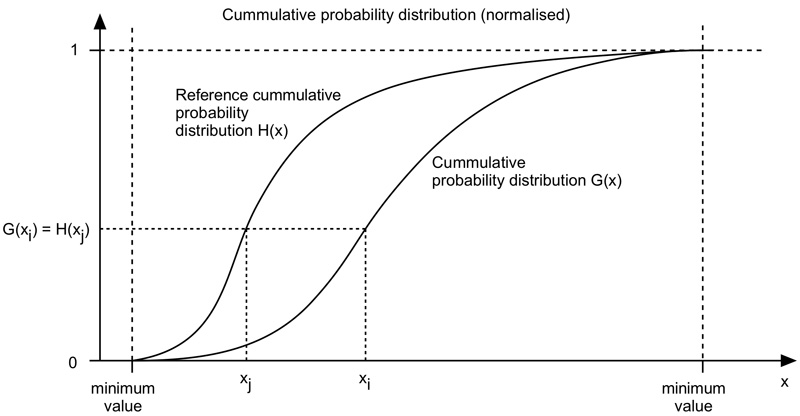
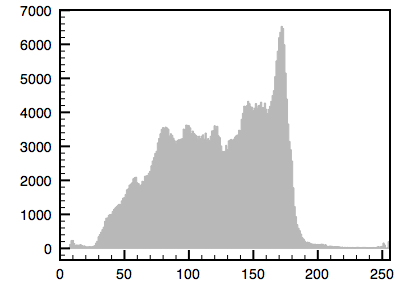
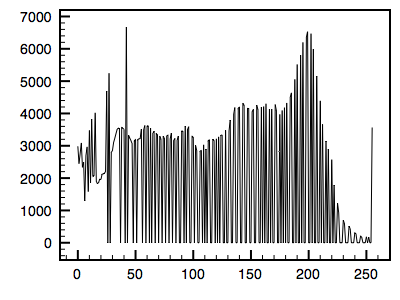
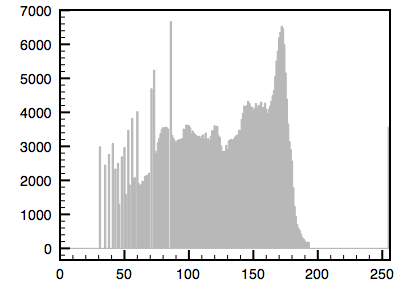
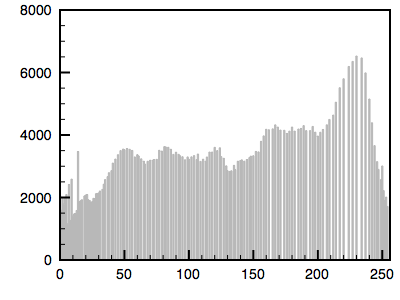
The following is an example using a greyscale image. The first image is the reference image and the histogram is given. The second image is the one whose histogram will be matched to the first. The third shows the resulting matched image.
Notes
Histogram normalisation (called "equalisation" in PhotoShop) is a similar process where the reference histogram is a uniform distribution (the cumulative distribution is a constant slope). The effect is to spread the data values over the available dynamic range. 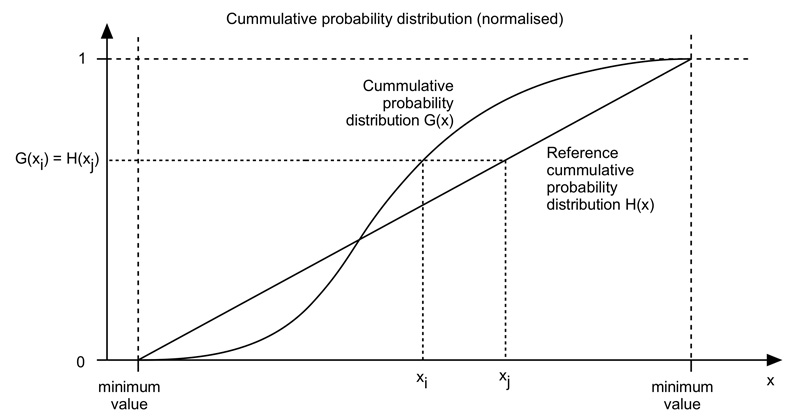
The figure illustrating the process is given above, it is the same as the earlier diagram except the reference cumulative probability distribution is a straight line rather than defined by a reference image. An example using the reference image used earlier is given below.
| ||||||||||||||||||