3D Reconstruction of a human bodySee original test subject
Software: MetashapePro and custom tools to control cameras
Translation into Georgian by Ana Mirilashvili.
The following is a report on the construction of a rig to capture photographs with the intent of using standard reconstruction software to create 3D human models. The application is the capture of athletes, namely swimmers, and as such one cannot rely on sufficient feature points on the subject. The initial approach was to paint the subjects in such a way so as to ensure sufficient feature points. This previous evaluation exercise was a test to both determine the best painting pattern, as well as determine the number of cameras required. Unlike the 3D reconstruction of inanimate objects, a human cannot reasonably stay still for more than a second or two. The more traditional 3D reconstruction with a single camera would require at least ten minutes, hence the use of a mannequin for the earlier testing. The solution then is to deploy multiple cameras that will be simultaneously triggered. Genlock is not required, the system as designed triggers the cameras to within 1/10 second, easily sufficient to avoid any movement for a subject who is told to stay as still as possible. The first build of the system is as follows. 
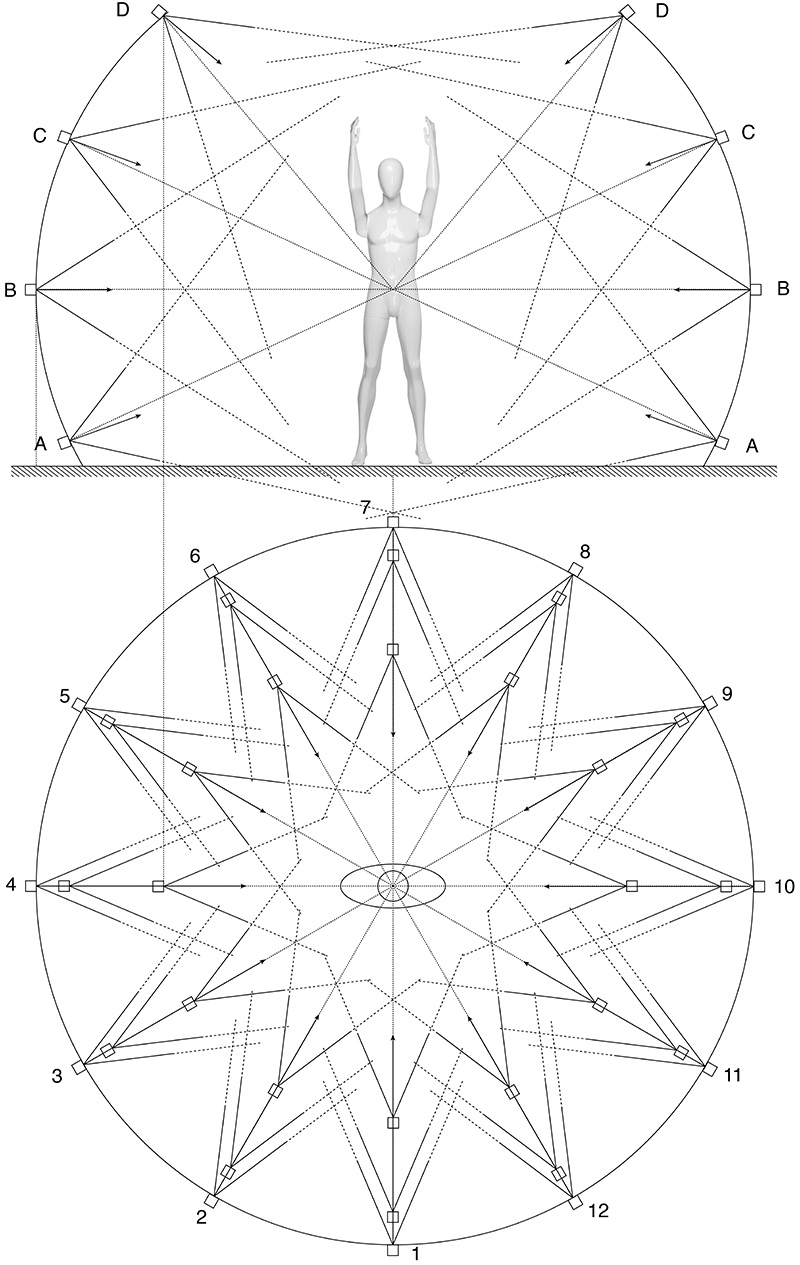 System specifications
Capture and processing pipeline
The typical capture sequence starts by taking a photographic set of a suitably texture rich calibration object. This serves to create accurate positions and orientations of the cameras. 
The second photographic set is a photograph of the space without any subjects, this is used to create masks for subsequent captures with the subject. The following shows a subsequent capture with the outline in white of the mask formed by simply subtracting the empty space image from the subject space image. This is obviously done per camera for a camera specific masking. Note: the cameras are in portrait mode. 
Resulting reconstructed 3D model as plain mesh and textured mesh. Depth maps shown also for each camera view. 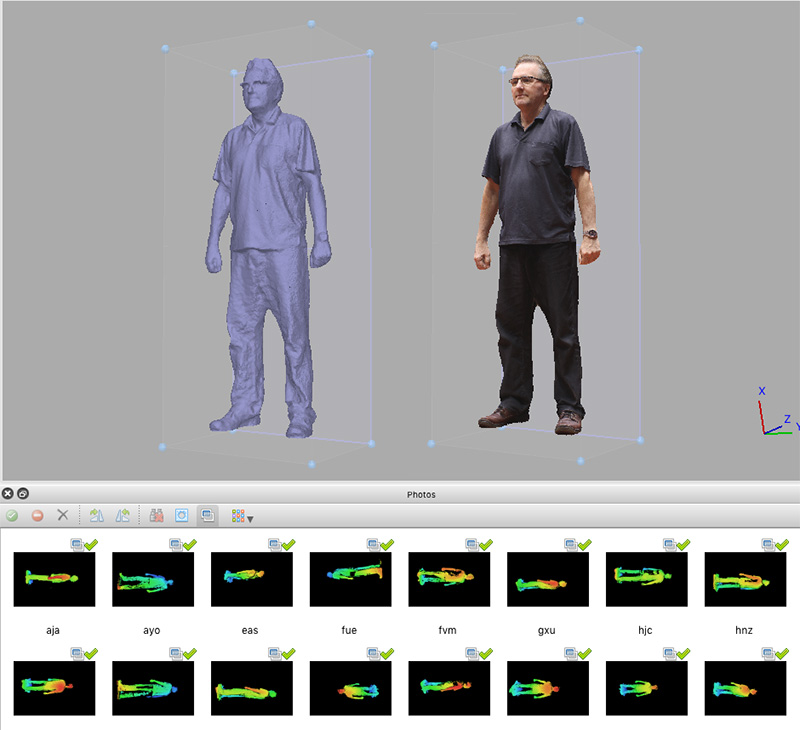
While there are a few things yet to do to improve geometric quality from the automatic processes, there is still expected to be some manual cleaning. In this case closing off the soles of the feet, removing partial glasses (clear glass is not likely to reconstruct through a photographic process) and smoothing rough surfaces. 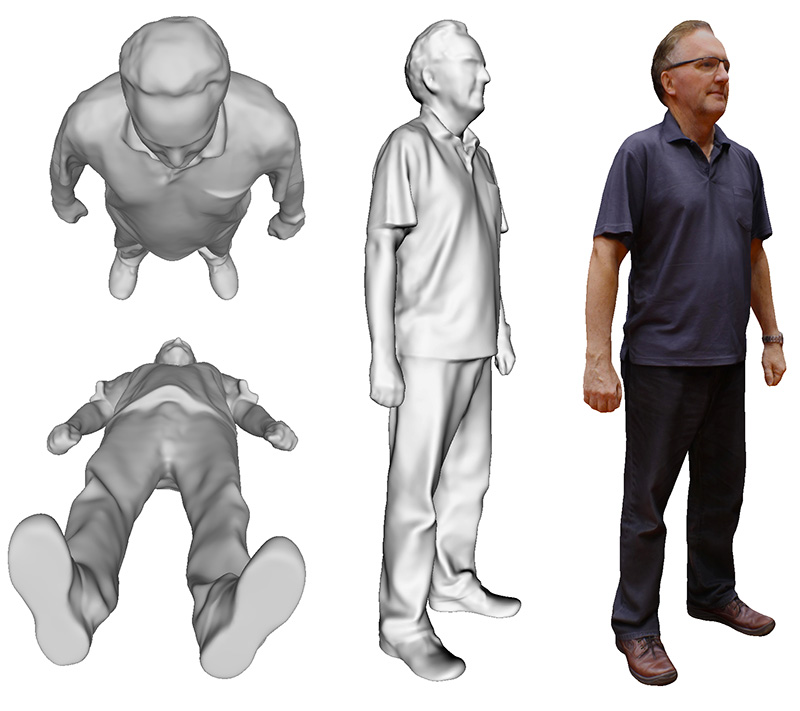
Some further test subjects from the installation and testing phase.  Models on Sketchfab
|